
If any single characteristic epitomises the software industry, it is change. This is an industry that is constantly evolving, morphing and occasionally making sharp shifts in direction. It operates in an environment that marries technology innovations with systems that have been in operation for decades. It is often more partisan that politics, and has groups of technology advocates that in any other scenario would be considered a cult.
In the midst of this maelstrom we look to deliver solutions to the market. And depending on whose statistics you read, we fail at rates of up to and beyond 60%. To emphasise the point, the suggestion is that we have a slightly better chance of successfully completing a software project than we have in predicting a coin toss.
Hmm, well that’s not going to meet the needs of the business, the budget or the market.
So why does it go wrong? And perhaps more importantly why does it go wrong with this level of frequency? How is is possible that these levels persist whether we use Waterfall or Agile methodologies?
There are two simple reasons in my opinion:
First we refuse to accept that software development is quite unlike any other endeavour that we undertake, it’s more complex, more volatile, and the more we try to simplify it, the more we disguise this fact.
Second, we insist on applying monitoring and control systems that work in other industries to the field of software development, where they are largely unsuitable. In effect, we are flying blind, and wonder why we don’t get what we expected.
Monitoring and Control Systems
Before diving in too deep, let me define what I mean by a monitoring and control system.
I’ve discussed elsewhere that we’re dealing with two systems when thinking about software development: the system that is being produced, and the system that is being used to produce that system. There’s a wider system of course, but we’ll be here all day if I try and deal with all that here.
Each of these has their own monitoring and control systems, the first governs the system that has been produced, often after it has been deployed, the second governs the process and reporting that is being used during development.
Let me introduce you to two gentlemen, Roger Conant and W. Ross Ashby. Messrs Conant and Ashby proposed a theorem that they named the Good Regulator. I’ll let you go down that particular rabbit hole at your leisure, but the generally accepted summary is:
Every good regulator of a system must be a model of that system
Conant & Ashby
For our purposes, the regulation we’re interested in is monitoring and managing the development process. To put it another way, if you’re going to regulate a system you must have a representative model of that system. If you don’t then you can’t be a good regulator. Makes sense, what you aren’t modelling, you aren’t regulating.
Another gentleman, said something similar many years earlier. A German fellow by the name of Einstein, who is considered quite smart by smart people:
Whether or not you can observe a thing depends upon the theory you use. It is the theory which decides what can be observed.
Albert Einstein
To put this all together, your model decides what you can see; what’s not in your model is not available to monitor, and by extension what you’re not monitoring you’re certainly not controlling.
Given the initial statistics on the failure rates of software projects, we clearly aren’t monitoring properly. I argue that this is because we don’t have anything close to a representative model of the development process. No model, no accurate monitoring; no accurate monitoring, no control.
That sounds closer to what we’re seeing.
The Available Models
The models we have for governing software development emerge from the methodologies that we have to hand. In general there are two: Waterfall and Agile. There are countless variations on those themes, but when you distil them back to their fundamentals, we’ve got one that says you can design and plan everything up front, and the other that says you are on a journey of discovery that can only allows for limited planning in short development cycles.
Waterfall
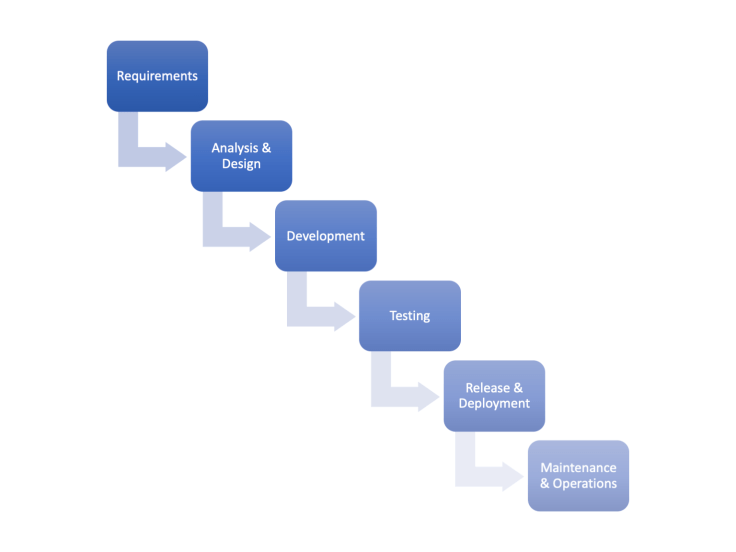
The waterfall methodology is premised on the fact that all of the needs of the project are known in advance, and as a result, a full architecture and design can be developed before a single line of code is written. One step logically follows another until the project is delivered. For most software systems, the waterfall methodology is a poor methodology.
Most, not all.
The natural report for waterfall projects is of course the Gantt chart, which closely reflects the methodology (thanks Henry Gantt).

Gantt started to produce charts in 1903, and continued to evolve them through the early part of the 20th century.It may surprise you to know that software development was not a widespread industry during this period. His work, and his charts resonated well with the emergence of scientific management (thanks Fred Taylor and Frank Gilbreth amongst others).
Scientific management techniques were the natural fit for software development when it first appeared in the late 1950’s and early 1960’s, but only because they were considered ‘modern’ but because the nature of programming at the time. Early software development used punch cards to submit the program to the computer, this was not ‘self service’. Programmers would prepare the punch cards, and these were handed over to the person working in the computer room for processing. Programming in this era was very similar to working on a production line. For this scenario, the waterfall methodology was a reasonable representation of the development process.
Punch cards were still in use up to the 1980’s (no, I never used them, but I know some of you were wondering).
As software development has progressed, Waterfall, including common techniques such as PERT and Critical Path Analysis don’t model how the vast majority of software systems are built. In this regard, it entirely fails our good regulator needs.
Interestingly, starting in the late 1940’s, Toyota started to approach manufacturing in a different way, largely in response to the challenges facing Japan in the post World War 2 era. This is the genesis of the Toyota Production System (TPS) and the foundation of the lean manufacturing approach. Lean manufacturing offered concepts and theories that inspired aspects of the second methodology.
Agile
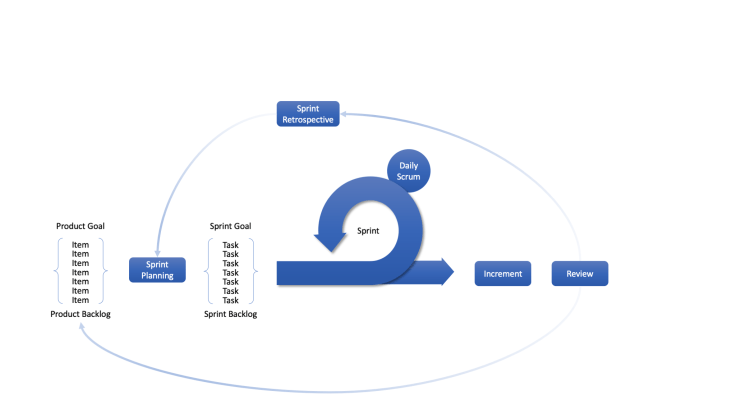
The agile methodologies, which emerged as a response to the problems with waterfall, were intended to produce a better and more effective approach to developing software systems. The agile manifesto didn’t actually propose any process, merely a set of behaviours.
Scrum emerged as the dominant agile methodology, and despite the misnomer it presented one of the earliest agile methodologies.
Other approaches emerged, many of which attempted to deal with the challenges of large scale development efforts, which received only light treatment in the original scrum approach. Kanban, lifted from the TPS, was actually one of the few substantially different agile methodologies.
In general, agile methodologies all agree on a couple of details including short work cycles, feedback loops for continuous improvement of the process and close collaboration between the business and the developers.
The basic report emerging from scrum is the burndown chart, which presents the completed tasks from the sprint backlog.
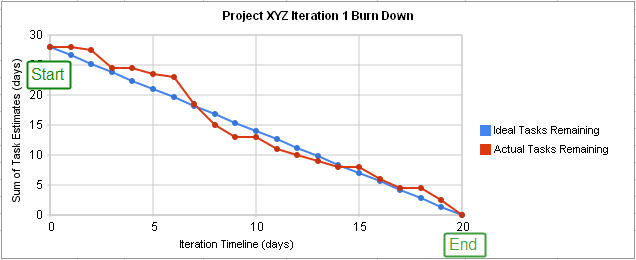
Image from Wikipedia
A constant topic of debate for any scrum team surrounds task identification. What constitutes a task in a sprint, and who should decide? Originally, the developers identified the tasks, owned the tasks, and were responsible for capturing the tasks – whether that was a sticky note on a board or into a tool. Over time, I’ve seen this responsibility gravitate towards the scrum master, which is a mistake. Developers feel less ownership of the task which contradicts the intended developer centric ethos.
I’ve also occasionally seen scrum tools turned into time tracking tools. I’ll be touching on this spectacular malfunction a little later.
At the macro level, agile methodologies do appear to be a closer analogue for the software development process.
Agile, in contrast to Waterfall fails in meeting the necessary information requirements for developing an accurate model. As I’ve discussed elsewhere (see Architecture and Agile), agile implementations regularly ignore the need for a system architecture, and the planning process leaves little time for actual design. The many compensating approaches, including parallel tracks are really just driving agile back to a state of mini-waterfalls. Agile methodologies also don’t fully model how software systems are built. They deal with a subset of the model and monitor that.
Thus, we fail again to meet our good regulator needs.
What are we Really Modelling
Anyone whose worked in software development over the last twenty years will recognise that the waterfall methodology is far removed from how modern software is developed. But waterfall has its merits. The discipline of establishing a scope for a project and developing a high level architecture have been put aside all too often, and all too quickly, by software developers who cherry pick the parts of agile that they like.
Agile, meanwhile has mutated from its earliest implementations into a form of lightweight waterfall, but without many of the positives. Naturally the enterprise architecture frameworks lean heavily on some of the waterfall disciplines, but awareness of TOGAF and its ilk is scarce.
Here’s the problem, in my opinion.
Waterfall captured tasks and put them into a linear model; Agile captures tasks and puts them in multiple cycles of linear models. Waterfall estimates tasks by duration (or function points if you want to get sophisticated); Agile initially estimated on duration but progressed to storypoints. Everywhere you find a software team estimating in storypoints you will find a frustrated project manager or financial controller running a calculation that converts them back to time.
Regardless of the methodology, we’re stuck in a mindset that is attempting to control the software development process using a form of time and motion study that first appeared at the start of the last century. The models that emerge from these methodologies are inaccurate representations of the system they’re intended to govern. And worse, the premise on which these models are being built is fundamentally flawed.
Regardless of which methodology is being used, we’re seeing a measure of just one thing: Developers writing lines of code. We’re back to the old KLOC days, where having developers grind out thousands of lines of code is interpreted as the only measure of progress.
There’s an assumption in all the methodologies that the tasks being completed are the right tasks, at the right time and are actually moving towards producing the system. But the models that they fail to incorporate all of the elements that would support confirmation of that assumption.
And the situation is degrading.
Consider the following…
Many projects, particularly in the early stages, rush to build an minimum viable product, and regularly without any real form of architecture. In another post (Architecture – Just Who Are We Talking To?) I highlighted questions that an architecture is intended to answer: Is this what we’re going to build, and is this going to work.
And yet, the models that we build, based on the methodologies that we adopt do very little to deeply connect the design of the system we intend to build with the tasks we’re tracking. We’re writing a lot of code, but the connection between that code and the desired outcome is outside of our model, and thus out of sight.
Next, agile methodologies, and particularly scrum, has a ‘Definition of Done’.
Do a survey of developers and the business and ask them what that means. Scrum states that it establishes everything that has to be complete before an increment can be declared ready for release. Many developers see it as an aspirational goal, often at the task level, representing the minimal set of code necessary before they can move on. The business see it as a final state for a capability, it’s done, right? No more work to do here.
If you’re active in the software development world, you’re either laughing or crying at this point. How can we monitor progress towards a goal when we can’t build consensus on what done means?
And finally, there’s new technologies. How does machine learning, or AI fit into a burndown chart? How do you fit these into your current methodology?
Closing Thoughts – Part 1
I’ve been spending a lot of time over the last couple of years looking at the challenges that we have with the software development process.
Not only are the current models failing us, I also believe that more comprehensive models are only part of the solution. We need to have a shift in our mindset; we need to rethink how we view software development and mature our understanding of what actually represents progress. This will offer the information that we need to support bringing projects to successful conclusions.
I’ll be dealing with many of these issues in Part 2.
I’ll leave you with a final quote from another clever person:
Anthony Stafford BeerThere is after all, no point in claiming that the purpose of a system is to do what it constantly fails to do.
Photo by Google DeepMind on Pexels

A nice train of thought applied to this area which we tend to ignore or just wave our hands about and say it must be so.
LikeLike