Behind the Curtain
The range of things that go on behind the veil of an API are legion. So much can be hidden here that it can very quickly become startlingly complex in a very short amount of time. I’m going to show the general approach that I take, which has served me well since the dinosaurs were killed off and the Internet emerged as a service delivery system.
The trick in my mind is to separate and isolate into layers early and often, with a view to collapsing those layers during an optimisation phase. You want to be as productive as possible without doing anything that gets you into trouble later. In many respects it reflects your life in your early twenties.
The Simplest Architecture for APIs
I can’t begin to enumerate how many systems I have built that follow this general architecture. From early WS-* systems for gaming, through telecoms systems to back office tools and middleware (in the broader sense) to financial system this is consistently my go-to architecture.
It offers almost nothing imaginative, creative or innovative to my development, but it is a solid framework to which I can logically add code. In very broad strokes it allows me to define a home for the functions that are needed to build out the API. These broad strokes involve the following elements:
- Middleware
- API Layer
- Logic Layer
- Repository Layer
So here it is, the big reveal
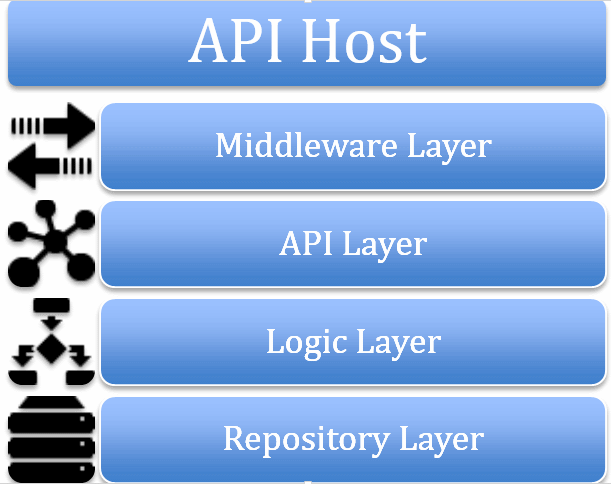
Recovering quickly from your disappointment at what looks like a four year olds guide to software architecture I’ll push on with the explanation.
Guiding Concepts
- Write your code in an object oriented (OO) fashion. Even if you think that your particular language of choice doesn’t work that way, you can make it so and should. It will save your blushes as some point.
- Learn Patterns – these ones will be a good start
- Singleton
- Factories and Abstract Factories
- Chain of Responsibility
- Decorator
- Inversion of Control (in Enterprise Patterns)
- Look up SOLID on Wikipedia.
- Single Responsibility
Every class should do one thing and one thing only. You decide what. If the class is starting to handle two or more things, split it so that you’re back to a single responsibility. - Open / Closed
I should be able to enhance the functionality of a class through extension (think inheritance or delegation) but I should not be able to rewire the class itself. - Liskov Substitution
I should be able to use an instance of any subtype of a class as a in the place of an instance of the class without breaking the program. - Interface Segregation
Only show what is required. A class may implement a single interface or multiple interfaces, but that implementation should be hidden from the consumer of the class by an interface. As far as the client is concerned, they can only do what the interface allows them to do. In the same way that your API is a contract for consumers, an interface is a contract for your code. - Dependency Inversion
Closely tied to interface segregation, I don’t need to know which class or classes are providing functionality I depend on. I get given an implementation of an interface that defines the services I depend on but have no direct knowledge of the implementation providing that service I just use the service. - Optimise Late
If you’ve kept with me up to now you should have a design that largely will get you some level of service delivered without too much pain. You need to have a little bit of self-belief at this stage ‘Trust your feelings’ as the man says. Only optimise when you’ve reached a certain level of stability with your API logic. Up to that point consider everything a potential candidate for change and therefore not ready for optimisation.
- Single Responsibility
Having laid bare the soul of so many production systems in one fell swoop, lets jump into each of the layers to see what they do
Middleware Layer
Your API will need to be hosted in some form of container, whether it be a full blown web server, or NodeJS in a Docker container you should expect certain capabilities to be available. I expect the host to provide a way to intercept the request / response at the very perimeter, even before it has been routed to the requisite API so that I can fiddle with the message early. This is what I call the middleware layer. I know it looks like its at the top but the diagram hides some inherent services from the host.
I always handle authentication in the middleware layer. Frequently I’ll add a generalised logging layer and often a telemetry layer for performance management and monitoring.
In many cases, although not always, my middleware layer will handle some form of validation on query parameters to ensure early detection of cross site scripting attacks or injection attacks.
My middleware layer will always have a handler for uncaught exceptions.
API Layer
Whether it’s RESTful or WS-* I keep the actual API layer very shallow. I really just want this to be a handoff to the logic layer. In my typical API layer I will deal with the verification of parameters and messages on inbound messages that are application specific, and not previously handled by the middleware layer.
Similarly I don’t really want it to get tin the way of responses. My API layers are responsible for translating the response codes from the logic layer into appropriate API level responses. For example in a RESTful service, a successful response from the logic layer would be translated into a HTTP 200 status code for return.
Logic Layer
The logic layer is the area where I end up with the greatest diversity of function in the APIs that I develop. In my world it exists to act as a glue layer between the public facing API and the back end systems that are being wrapped.
If the API is providing access to an enterprise system, the logic layer can be responsible for initiating and firing complex workflows as a result of input from the API layer, or it might be as simple as translating messages into an appropriate format for the repository layer.
Given the rich ecosystem that WS-* services offer for orchestration and transaction management, I’ve often found that these services are managed external to the API. RESTful services in contrast are poorly serviced in these areas and it is these operations that exist in the logic layer.
In practice, the logic layer is where all the work is actually done. The nature of the logic layer is a key determinant in choosing a technology platform for your API. If the API needs to perform complex processing then NodeJS may be a bad choice for example, conversely if your API is a simple wrapper around a data storage layer then NodeJS may be the best choice.
Repository Layer
If the API layer is thin and the Logic Layer is complex then the Repository layer is the neurotic layer with body image problems.
The first thing to notice is that I call it a ‘Repository’ rather than a persistence or storage or database layer. Borrowing a little from the fine work of the Domain Driven Design camp, I want this to convey the concept that this is where data lives without it making any reference to its lifetime or long-term storage mechanisms. If this seems particularly rational, pedantic or even well reasoned then you should prepare yourself for disappointment as we move on. Pretty much everything else that follows is a bit subjective at best. Also the word has the potential to be misspoken which then makes the entire discussion sound a bit rude!
The data that is going to live beyond a single session needs to be stored in some form of repository, whether it is a database, a memory cache or some fantastic appliance is largely irrelevant from the perspective of the logic of the system. Extending that principle we can also agree that the logic layer shouldn’t know what grinders the data needs to be put through to actually achieve this storage. So the repository layer is the place where the logical data gets transformed from the form it takes when being processed by the logic to the form it takes when being stored and vice versa.
Things start off fairly easily in the repository layer, we want to support the standard CRUD (Create, Read, Update, Delete) operations and given the logical one to one correlation between the data being used in the logic layer and the data being stored in the repository layer we can make excellent headway at the early stage of development. It’s queries and their results that really scupper our efforts.
If you’ve diligently read all that has gone before you’ll immediately see the problem. I’ve previously asserted that the query that results in a collection of data should not return that full collection in a single call. I’ve also stated that the collection returned should be a summary of the data, not the full data for any given item. Its easy to fall into the trap of ensuring that all logic exists in the logic layer, which would naturally lead to the conclusion that this manipulation of data to produce a summary should occur in the logic layer.
In the hope of sidestepping the possibility of contradicting myself, I’m going to show a set of guidelines for a repository layer that hopefully help inform the decision for you.
Rules of the Repository
- Make the decision on NoSql vs. RDBMS at the start; design and build for that.
A well structured repository layer will offer some protection should you later decide to shift technologies, but no matter what it’s at best minor heart surgery to move between them. I’ll talk more about these technologies a little later. - Always remember the fundamental rule of data storage regardless of technology – always seek to minimise disk I/O.
You might think that this old aphorism is irrelevant in a world of SSD storage – you’re wrong. Efficiently managing the movement of data from storage to memory is still the most common performance bottleneck in any API. - If you’re using a Relational Database, use an Object Relational Mapper (ORM) – Hibernate for example – yes its performance is not as good, but you won’t notice in the short term; yes it’s a lot of bloat, but you’re building functionality first and yes you’ll probably get rid of tit later but that’s an optimisation question also for later.
The productivity gains you’ll get from starting with an ORM will release the dependent people or teams much more quickly than if you hand crafting every minute element of the repository. Better to have those people productive in parallel than hold them up while you tinker with some new technology. - Design your repository layer to have a one to one correlation between logical elements and repository implementations – for example, if you have a customer as a primary concept then you should have a customer repository.
- Data is data and logic is logic. Remember that the classes you implement for moving data around are just that.
I’ve been forward and back on this for decades (literally). Early in my career, when OO was still a buzzword and The ‘A’ Team was on TV for the first time there was a trend to encapsulate behaviour with data in a single class. You could say object.Save() and it magically knew how to do this. All it led to was a rubbish way to write code that raised more barriers to clarity and simplicity than I care to mention.Think about it this way, you are moving data across wires, or through the air as the case may be. You are not moving behaviour; that is something that exists at the source and the destination and indeed may be different depending on where it is being used. The need for separation should be clear. Repository implementations do something on the objects carrying the data. The objects carrying the data are as dumb as a manila folder. - Keep CRUD operations and query operations separate. I tend to have two interfaces, IRepository and IQueryableRepository (yup that’s what I call them!).
IRepository is the interface for CRUD operations, so no results with multiple elements. IQueryable by contrast only does queries (who would have guessed?) and does not have the slightest notion on how to store or update data. - If you have a query that crosses multiple entities, for example the result of a multi-way join it probably deserves to be in its own repository class, or in an isolated analytics repository class.
- As a matter of course I make repository layer / logic layer decisions based on the location of the data. So if I have two logical data elements and both live in the same store, or the same database, then I can join them together in a single operation. That operation, for me, properly exists in the repository layer. If the two entities come from different stores, one from a database and one from an API call on a third party system, then this is a logical join which belongs in the repository layer. This opinion is entirely subject to change at the slightest whim, which leaves me hunting the source of data more often than I care to mention.
Final Pointers, Hints and Code
I’m not noted for my memory. This is particularly true when it comes to code in specific projects. I’m more likely to need to look at my code to see what I was doing than immediately remembering what I did. The upshot of this particular deficit in my abilities is that I tend to write fairly expansive code that I might later collapse down.
Enter the Decorator Pattern. I can honestly say I use this all the time…
Decorating for Success
Accepting a scenario where I want a customer records repository, but I want it to use a cache, timing, telemetry and logging.
You can already guess that your initial instinct to bunk all of this functionality into a single implementation is wrong (right?). Nope following our ordinance of single responsibility, we’re going to take the higher road on this one, writing a bit more code, but ending up with a much higher degree of both flexibility and control as we go.
Remember SOLID? We’re going to run through SOLID for these examples, but not necessarily in the order defined.
Lets start with the interface segregation (I), which will define the contracts that control what we’re doing; we need two pieces, data contracts and interface definitions:
All code is in c# but should move to other languages fairly easily
Data Models:
public class Customer
{
public string Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string Email { get; set; }
public string ContactNumber { get; set; }
}
public class CustomerSummary
{
public class CustomerSummaryItem
{
public string Id { get; set; }
public string DisplayName { get; set; }
public string Email { get; set; }
public string RefUri { get; set; }
}
public CustomerSummaryItem[] Results { get; set; }
public int TotalResults { get; set; }
}
Note the rather elegant nested class here – you’ll need it later and won’t be able to find it.
Interfaces
I’m cheating here a bit by using generics, it allows me to define a single interface for concrete repositories that vary only by the type of data being stored.
public interface IRepository<T>
{
bool Create(T data);
T Read(string id);
bool Update(T data);
bool Delete(string id);
}
public interface IQueryableRepository<T>
{
T[] GetSummaries(int startAt = 0, int take = 20);
}
So now we have the basis for our repository, we know the structure of the data that we’re going to pass around and we know what behaviours we need our repository to exhibit. Lets push straight into the repository itself which we want to adhere to the S, and the I of SOLID in one fell swoop:
The Concrete Repository
internal class CustomerRepository : IRepository<Customer>, IQueryableRepository<CustomerSummary.CustomerSummaryItem>
{
public bool Create(Customer data)
{
return true;
}
public Customer Read(string id)
{
return new Customer();
}
public bool Update(Customer data)
{
return true;
}
public bool Delete(string id)
{
return true;
}
public CustomerSummary.CustomerSummaryItem[] GetSummaries(int startAt = 0, int take = 20)
{
// read forward 'startat' records
// take the next 'take' records
return new CustomerSummary.CustomerSummaryItem[10];
}
}
There are a couple of things to note here:
- The class is declared as internal, which is c# for saying I don’t want this to be directly instantiated outside of the module where its declared. We’ll create a factory later to handle the actual creation
- We’re implementing both the repository and queryable interface in this single class, but instead of using a generic parameter, we’re explicitly implementing using the Cusomer and CustomerSummaryItem classes.
- This class doesn’t actually do anything, but then again I have to leave some work for you to complete.
- The goal for caching, timing, telemetry and logging are not here.
So where do we put all of this other functionality?
Referring back to our SOLID principles we only want a single use, which in this case is the storage of data, not the logging, timing or all the other requirements. Similarly, we only want the functionality of this class to be accessed through its interfaces, which will be really important very shortly, so we declare it internal.
Adding Logging and Caching
If you’re still with me you’ll know that I’m about to create two more classes, one that performs logging and one that performs caching.
We’re going to use the Decorator pattern, which is a form of a wrapper that adds functionality and then delegates to the class being wrapped. This same effect can be achieved using a chain of responsibility pattern or through simple inheritance but the side effects of these approaches are greater than using decorators.
Logging
class QueryLoggingDecorator : IQueryableRepository<T>
{
private readonly IQueryableRepository _component;
public QueryLoggingDecorator(IQueryableRepository component)
{
_component = component;
}
public T[] GetSummaries(int startAt = 0, int take = 20)
{
Console.WriteLine($"Logging start of find from {startAt} to {take}");
return _component.GetSummaries(startAt, take);
}
}
The trick here is to declare a class that implements the exact same interface as the class it’s wrapping. When a call comes in to its GetSummaries method, it logs it and then passes the request on to the component that it’s wrapping. That may seem like a lot of work for little benefit, but bear with me for the minute, and you’ll see how powerful this approach can be.
Caching
The caching decorator starts to expose the value of this approach. In this case, we’re doing a specific implementation of the interface as this cache is for a specific type of item. This decorator gets the call first to get customer summaries. It checks the internal cache to see if it can satisfy the request from cache. You’ll need to ignore the horrible key being used. If it can it will return that data. If it can’t then it drops the request to the class being wrapped and caches the response before returning. Thus the next call in will be satisfied by data from the cache.
class CustomerQueryCachingDecorator : IQueryableRepository
{
private readonly IQueryableRepository _component;
public CustomerQueryCachingDecorator(IQueryableRepository component)
{
_component = component;
}
public CustomerSummary.CustomerSummaryItem[] GetSummaries(int startAt = 0, int take = 20)
{
var cache = MemoryCache.Default;
var key = $"DataHack.Customers{startAt}-{take}";
var cachedData = cache[key] as CustomerSummary;
if (cachedData == null)
{
var retVal = _component.GetSummaries(startAt, take);
if (retVal != null)
{
cachedData = new CustomerSummary
{
Results = retVal
};
// Cache for 10 hours
cache.Add(key, cachedData, DateTimeOffset.Now.AddHours(10));
}
}
return cachedData?.Results;
}
}
Pulling it all together
If that all seems a bit abstract, its only because I haven’t shown you how all of this will come together, whilst also satisfying the D in SOLID.
In this style of coding, a factory constructs our objects. I should note that the many dependency injection engines are factories at their core. Here’s our factory:
public static class RepositoryFactory
{
public static IRepository GetCustomerRepository()
{
var core = new CustomerRepository();
var telemetary = new RepositoryTelemetary("CustomerCategory", core);
return telemetary;
}
public static IQueryableRepository GetCustomerQueryRepository()
{
var core = new CustomerRepository();
var caching = new CustomerQueryCachingDecorator(core);
var logging = new QueryLoggingDecorator(caching);
return logging;
}
}
Looking at the GetCustomerQueryRepository method you can see that it initially creates the concrete repository. It then creates our caching decorator passing in the core – the cache now wraps the concrete repository. Next it creates the logging decorator, passing in the previously constructed caching object before returning.
When a consumer of this interface calls GetSummaries, the call will first be logged, then the cache will be checked before finally dropping down to the concrete repository to be satisfied. The consumer has no idea that all of this is happening – it just looks like a call to GetSummaries.
I can remove logging or caching by simply changing this factory method without a single change to any other code – and that my friends is the power of the decorator and factories.
